







 Adam Keith Milton-Barker 6704 2025-01-11
Adam Keith Milton-Barker 6704 2025-01-11
In my previous article I provided a short introduction to AI PCs and the Khadas/Intel AI PC Development Kit, a development kit that allows developers to take advantage of Intel CPUs, GPUs, & NPUs to develop and run AI and GenAI applications on the edge. In this article I will take you through the basics of setting up your AI PC, installing OpenVINO & OpenVINO GenAI, and running facial landmark detection with WebNN, and Meta Llama 3.2 completely locally with OpenVINO.
If you like, you can check out my previous article to find out more about AI PCs and the AI PC Dev Kit. If you do not have an AI PC you can purchase one from the Khadas website.

Intel’s Neural Processing Unit (NPU) is an AI accelerator integrated into Intel Core Ultra processors, designed to handle complex AI tasks quickly and efficiently. Built with Neural Compute Engines that process massive data in parallel, NPUs excel at operations like matrix multiplication and convolution while consuming less power than traditional CPUs or GPUs. This not only boosts AI performance but also frees up system resources for other tasks.

OpenVINO™ is an open-source toolkit by Intel, designed to optimize and deploy deep learning models across a range of tasks including computer vision, automatic speech recognition, generative AI, and natural language processing. It supports models built with frameworks like PyTorch, TensorFlow, ONNX, and Keras.

OpenVINO™ GenAI is designed to simplify the process of running generative AI models, giving you access to top Generative AI models with optimized pipelines, efficient execution methods, and sample implementations. It abstracts away the complexity of the generation pipeline, letting you focus on providing the model and input context while OpenVINO handles tokenization, executes the generation loop on your device, and returns the results.

The Web Neural Network API (WebNN) is opening new doors for web applications by bringing accelerated machine learning directly into the browser. No need for external servers or clunky plugins—WebNN taps into the power of modern hardware like CPUs, GPUs, and NPUs. This means faster response times and real-time AI-driven solutions that can operate smoothly even in scenarios where every millisecond counts. It's a step forward for those of us pushing technology beyond the conventional limits and into everyday life.
In some cases your AI PC will come preloaded with everything you need, but this walkthrough will help you if you ever start from scratch.
The first thing you want to do is ensure that you have all the Intel drivers you need. On your AI PC, search for Intel® Driver & Support Assistant. When you click to open the assistant you will be redirected to the Intel® Driver & Support Assistant page. From here, download and install any available drivers.
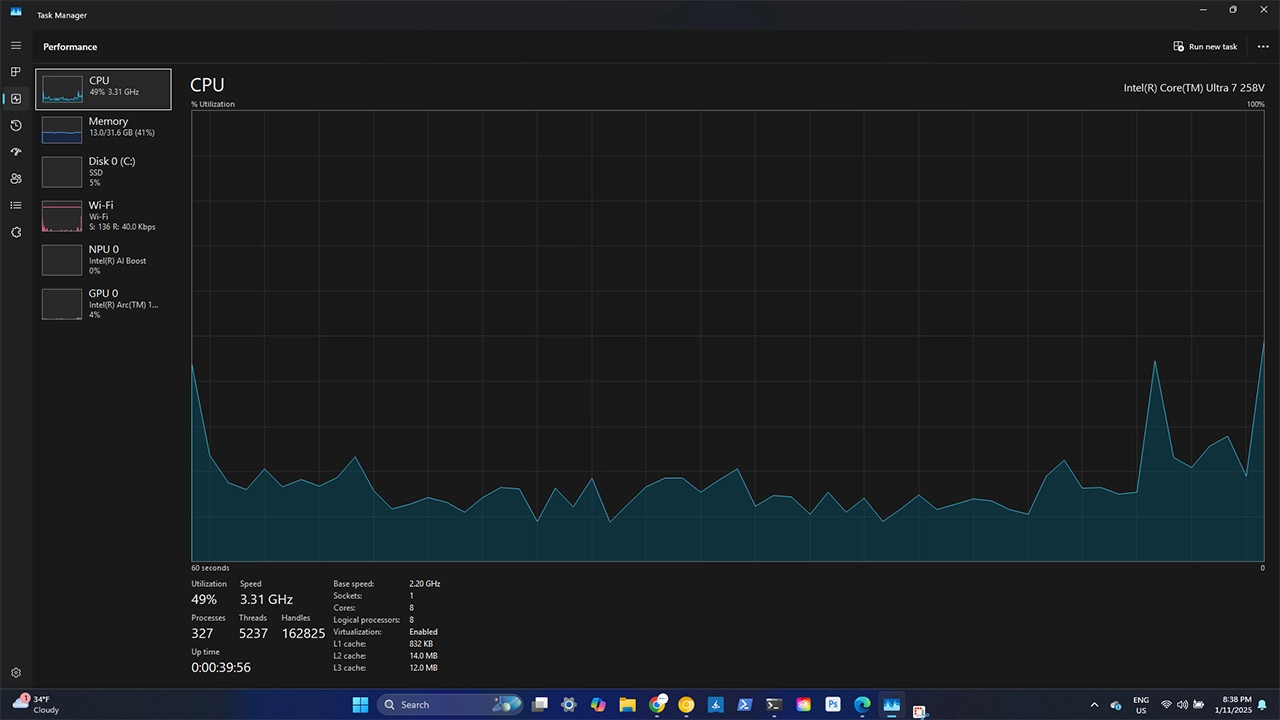
If you open up Task Manager and switch to the performance tab, you will find detailed information about your system, including the ability to monitor in real-time your CPU/GPU and NPU usage. We can use this throughout this tutorial for monitoring our usage whilst using the examples.
We will install Intel's OpenVINO GenAI and run Meta Llama 3.2 on our AI PC. To get started open your PowerShell as administrator and use the following commands.
cd C:\Intel
git clone https://github.com/openvinotoolkit/openvino.genai.git
git clone https://github.com/openvinotoolkit/openvino_notebooks.git
python -m venv openvino_venv
openvino_venv\Scripts\activate
pip install openvino-genai --extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly
pip install --extra-index-url https://download.pytorch.org/whl/cpu "git+https://github.com/huggingface/optimum-intel.git" "git+https://github.com/openvinotoolkit/nncf.git" "onnx<=1.16.1"
cd openvino.genai/samples/python/chat_sample/The above commands will navigate you to the Intel directory on your C drive, clone the OpenVINO GenAI and OpenVINO notebook repositories, create a virtual environment and activate it, and then install the required packages before navigating you to the chat_sample directory.
Before we go any further, do a quick check to ensure that OpenVINO and GenAI is installed correctly for Python.
python
from openvino.runtime import get_version
print(get_version())
import openvino_genai
openvino_genai.__version__ You should see the following:

Next you want to modify the existing chat example. To do this open the chat_sample.py file in your editor and change line 21 to:
device = 'GPU'And line 25 to
config.max_new_tokens = 2048Meta Llama 3.2 is a gated model on Huggingface which means that you need to accept the license before you can use it. To do so visit this link. Once you have completed that step, you can run the following code:
optimum-cli export openvino --model meta-llama/Llama-3.2-3B-Instruct --task text-generation-with-past --weight-format int4 --group-size 64 --ratio 1.0 llama-3.2-3b-instruct-INT4The above command uses Intel Optimum to convert the Llama 3.2 3B Instruct model from Huggingface into an Intermediate Representation (IR) format that is compatible with OpenVINO, this will allow us to run the model on our AI PC.
The above command can take some time depending on your internet connection, so it may be a good time to grab a coffee.

Once the conversion has completed you should see similar to the above output. If you CD into the llama-3.2-3b-instruct-INT4 directory you will see the files output by the command. Now we have everything ready, we can run the sample:
python chat_sample.py llama-3.2-3b-instruct-INT4Go ahead and ask some questions:
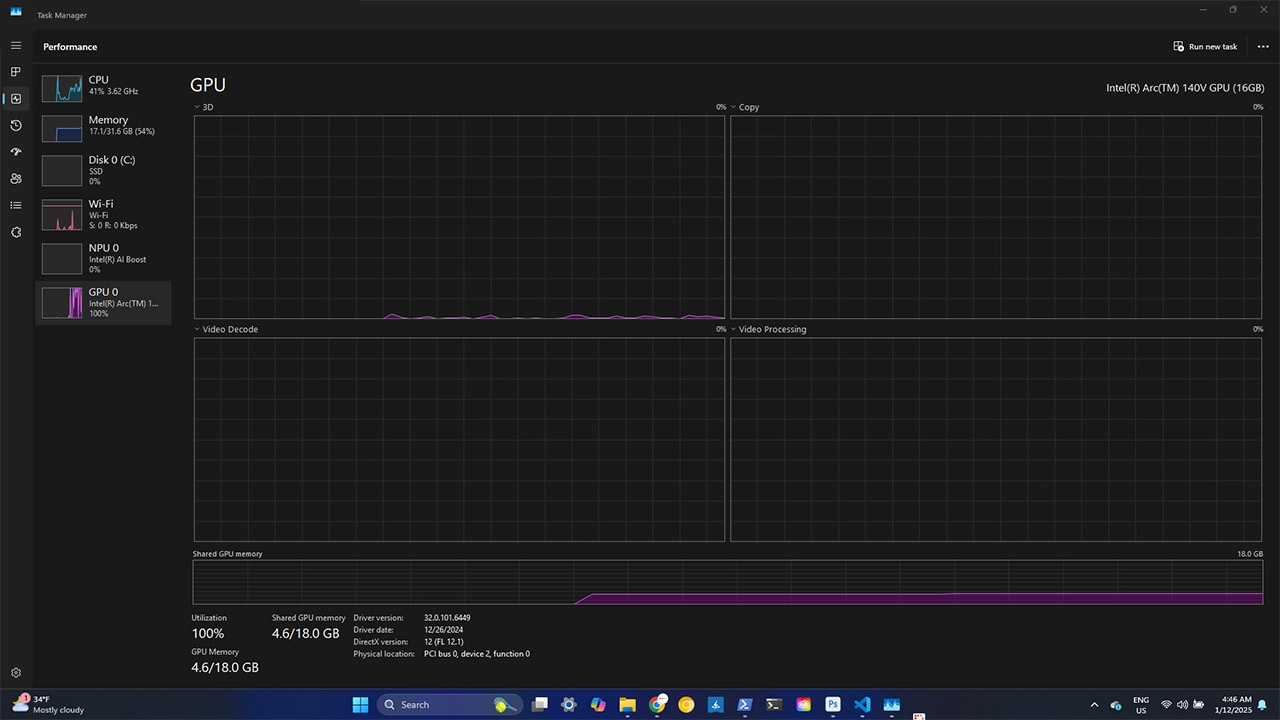
If we take a look at Task Manager we will see that during the output generation the model is consuming 100% of the GPU and roughly about 5.0 GB of memory.
For the final part of the installation we will set up webNN. First of all use the following command to download the WebNN repository. This may take some time to download.
git clone --recurse-submodules https://github.com/webmachinelearning/webnn-samplesDownload and install Google Chrome Canary for Windows 11. Once installed open up the browser and navigate to chrome://flags. Find Enables WebNN API and change it enabled and then relaunch the browser. Now that we have everything installed we will try out the WebNN samples. Use the following commands to start the webDNN server:
cd C:\Intel\webnn-samples
python -m http.server -b 127.0.0.1 8000Once the server is started, open up Chrome Canary if it isn't already and navigate to http://127.0.0.1:8000
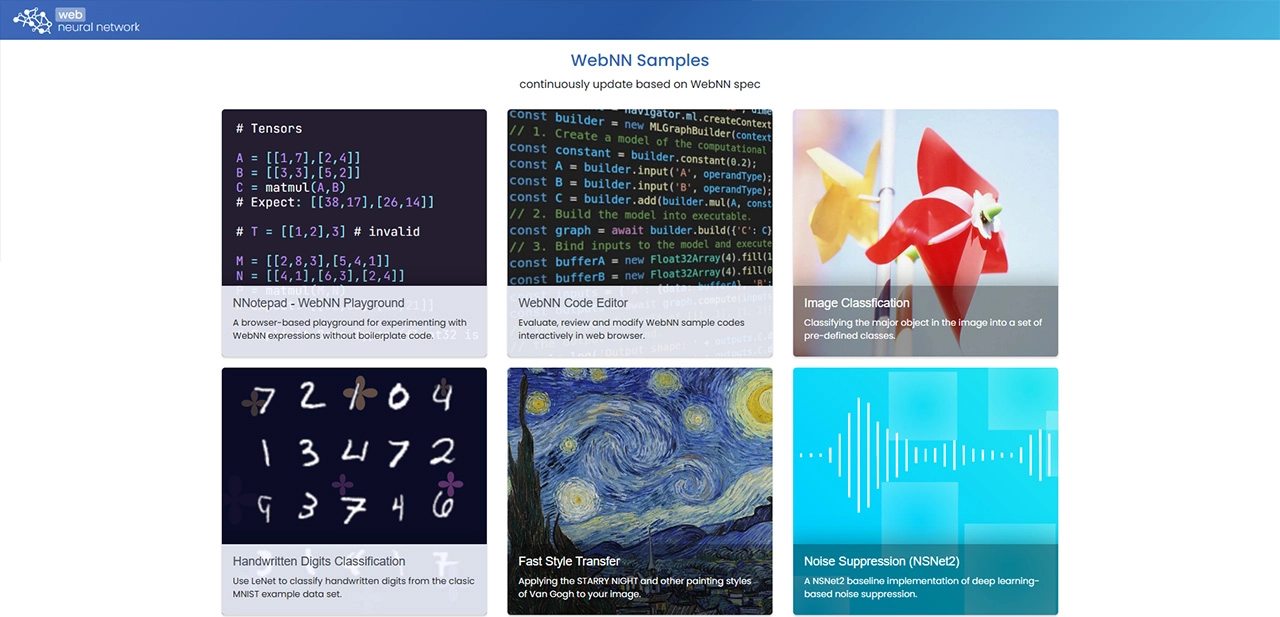
Here you will find a number of examples, to get started with webNN we will use the Facial Landmark Detection example. For this example you can use an image or a webcam, for best results make sure you have a webcam connected to your AI PC. Scroll to the bottom of the examples and click on the Facial Landmark Detection example.

Select GPU for the backend, and select SSD MobileNet V2 Face for the FaceDetection setting. Finally select LIVE CAMERA.
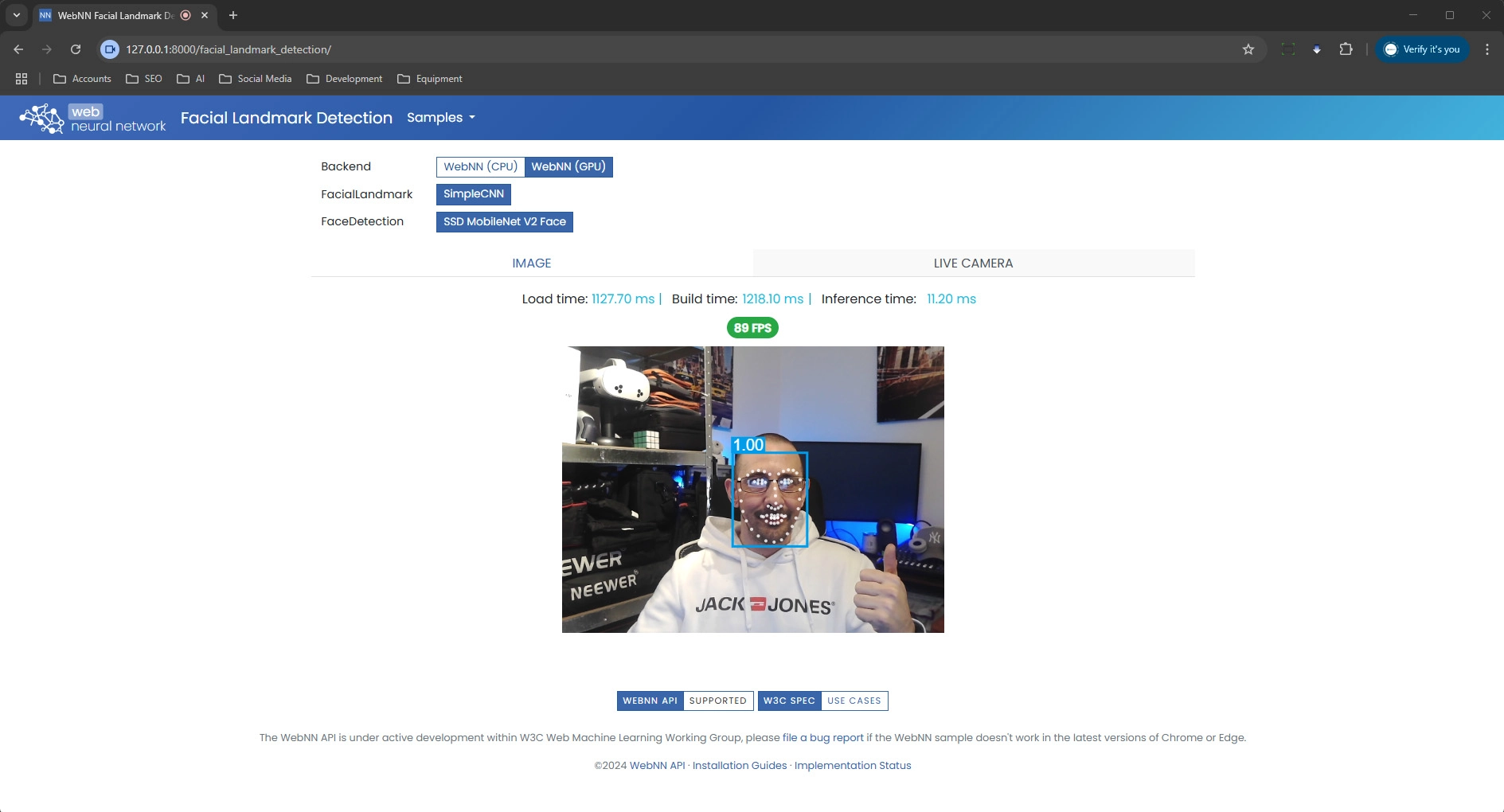
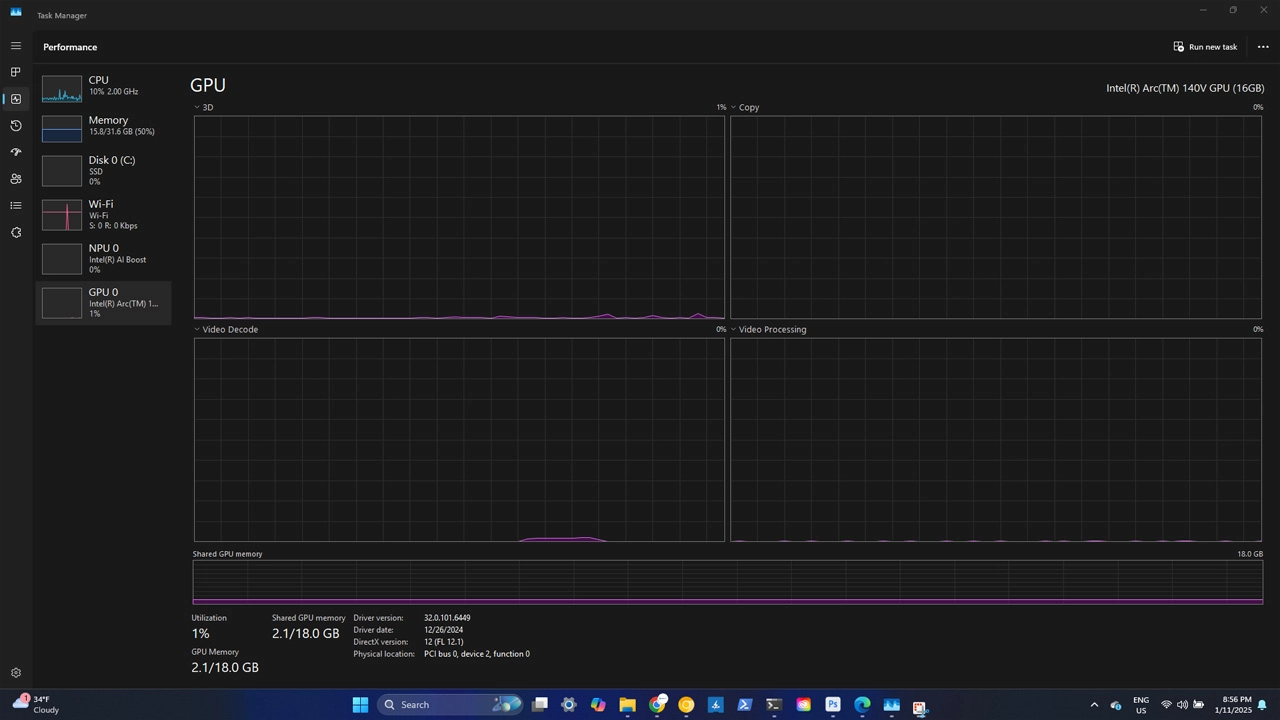
Once loaded you will see a live stream of your camera with the facial landmark detection overlay. If you look at Task Manager, you will see that this example is barely even touching the GPU and using roughly 2GB of memory.
I hope you have enjoyed this tutorial and found it useful. In the near future we will be releasing some open-source projects including the 2025 version of GeniSysAI and TassAI, and CogniTech CORE Local for AI PC that will allow CogniTech CORE customers to take advantage of local LLMs with the use of Intel AI PC.
If you have any questions with getting started with your AI PC, please feel to reach out and I will be happy to assist where possible.

Adam is founder and Managing Director of CogniTech Systems LTD and creator/primary developer of the CogniTech CORE platform. Adam is an Intel Software Innovator, NVIDIA Jetson AI Specialist/Ambassador/Certified DLI Instructor, and part of the Edge Impulse Expert Network.
View Profile View Linkedin View Website View Github